How To Save Money Without Sacrificing On Reliability When Using AWS Spot Instances
By Sridhar Kakkillaya | 7 minute read

Introduction
As a large email security service provider, MailChannels is also a long time Amazon Web Services (AWS) customer. To reduce our operating overhead, we’ve invested heavily in engineering to scale our infrastructure dynamically. One of the best tools in our cost-saving arsenal is a technology offered by AWS called Spot Instances. In this article, we’ll discuss how we use Spot Instances to reduce our operating costs, without sacrificing on reliability.
What are “Spot Instances”?
Cloud providers like Amazon Web Services (AWS) maintain excess capacity so that computing resources can be made available on short notice to customers who have a need to scale up quickly. To encourage greater utilization of resources that would otherwise be left idle, AWS lets its customers rent excess capacity at a greatly reduced price (up to 90% below regular pricing) through a sort of market called “Spot Instances.”
Spot Instance pricing is dynamic and personalized: You set the price you are willing to pay and then Amazon either allows you to obtain instances at that price, or indicates that none are available. Once you have acquired Spot Instances and are using them, if the current, or “spot,” price exceeds your maximum bid price, or if AWS runs out of capacity for the type of instance you want to use, then the Spot Instances you are using will be terminated in favor of others who are willing to pay more.
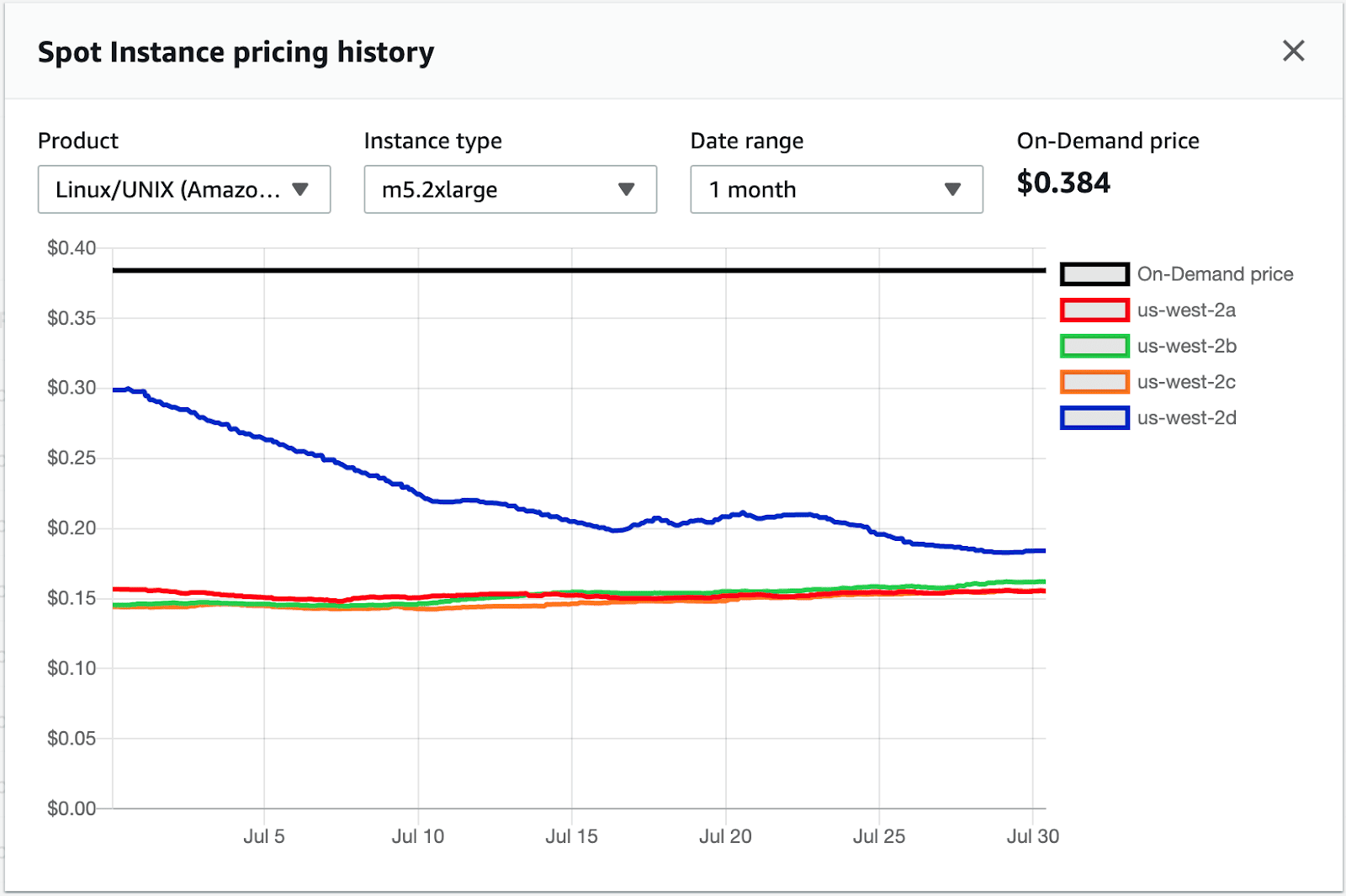
Figure 1: For an m5.2xlarge instance, the on-demand price is $0.384 and the spot price $0.15. This represents a savings of ~60%. Usually, there is variability in the prices depending on the availability zone.
Isn’t it bad if Spot Instances can just be terminated? Spot Fleet to the rescue.
On the surface, having an instance terminate from underneath you sounds like a pretty bad idea. After all, if you’re offering an always-on services like email delivery, having a machine suddenly terminate would presumably leave customers without service. Thankfully, back in 2015, AWS introduced a feature called Spot Fleet, which enables spinning up multiple types of spot instances, each with a different bid price. If an instance type runs out of capacity and gets terminated, a different instance type gets spooled up immediately based on our specifications. Because the probability of all the instance types running out of capacity is small, chances are there will always be enough compute capacity to fulfill our computational requirements.
Spot Fleet is analogous to a transit service having some extra buses of various kinds sitting in reserve, ready to take over in case — as is inevitable — some of the operating buses break down. You might not get the type of bus you were previously using, but so long as you can move the same passengers into the replacement buses, things will work out just fine.
How we did it
At MailChannels, we use Kubernetes to orchestrate hundreds of services across a diverse fleet of AWS resources. To make use of spot instances in a way that saves the most money, we draw on a combination of Kubernetes add-ons and capabilities, including Instance Groups, Cluster Autoscaler, Horizontal Pod Autoscaler, Kubernetes Spot Termination handler and Cluster Overprovisioner.
Using Instance Groups to provision services across the right types of instances
Some aspects of the MailChannels service are stateful and others are stateless. A stateful service must maintain state information such as a persistent data structure whereas a stateless service can respond to requests without relying on any stored state information. Since spot instances can be terminated at any time, storing state within a spot instance is problematic, since that state information is destroyed when the spot instance goes away.
To ensure that stateful services can have their state persist as needed, we use the InstanceGroup resource type to group together instances based on whether they are stateful or stateless. Stateful services are then provisioned onto an InstanceGroup made up of on-demand (i.e. traditional) AWS instances; stateless services are provisioned onto an InstanceGroup made up of spot instances.The separation of services is achieved through the use of Kubernetes labels.
Using labels to identify stateless and stateful services allows us to rapidly migrate load off of spot instances and onto on-demand instances in case the spot market becomes too expensive or if spot instances are unavailable.
Using Cluster Autoscaler to automatically provision capacity
With Instance Groups taking care of the allocation of spot and on-demand instance types, we can then rely on Cluster Autoscaler to automatically provision and deprovision Kubernetes nodes (i.e. instances) in response to fluctuating demand. We tell Cluster Autoscaler when various performance parameters are starting to lag – things like message processing latency, for instance – and it responds automatically by adding capacity through new instances. Similarly, when parameters indicate that too much capacity has been provisioned, Cluster Autoscaler removes instances. Instances are automatically added and removed within the spot fleet or the on-demand fleet depending on where the capacity is needed. In other words, if we need additional capacity for stateful services, Cluster Autoscaler will bring up new on-demand instances.
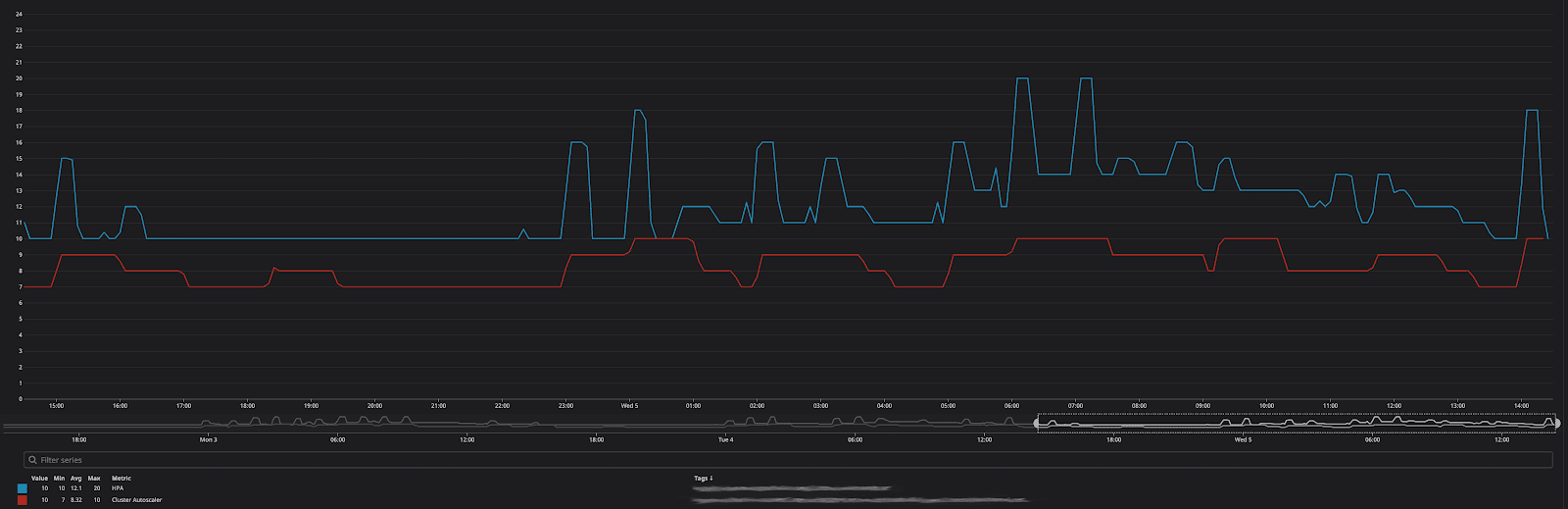
Cluster autoscaler & horizontal pod autoscaler in action. In response to email volume and other metrics, pods and cluster nodes are scaled up and down throughout the day.
Using Horizontal Pod Autoscaler to allocate pods efficiently
Horizontal pod autoscaler automatically scales the number of pods in a replication controller, deployment, replica set or stateful set based on observed CPU/memory utilization or based on custom metrics. In our case, we use a combination of CPU and email volume to scale the core services.
Handling spot instance termination with Kubernetes Spot Termination Handler
When AWS wants to terminate a spot instance, AWS provides 2-minutes’ notice of the instance’s termination so that you can adapt to the forthcoming loss of capacity.
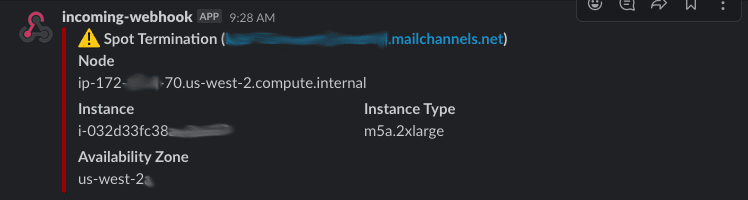
The Kubernetes Spot Termination Handler periodically polls the EC2 Spot Instance Termination Notices endpoint. When a termination notice is received, the spot termination handler will try to gracefully stop all the pods running on that Kubernetes node and move the pods to a node that has capacity available. You can even set it up to send slack alerts whenever the termination notice is received; an example spot termination notice is shown below as it appears in Slack:
Using the Cluster Overprovisioner to keep some spare capacity in reserve
While we’d like to run our infrastructure in the leanest possible manner, it pays to have some spare capacity available at all times, just in case a surge of traffic arrives unexpectedly — something that happens with alarming frequency in the world of email filtering.
Cluster Overprovisioner allows for overprovisioning of cluster nodes when nodes need to be quickly scaled up without waiting for the cluster autoscaler to bring up a new node, a process that can take several minutes.
Spot Instance Types
Cluster Autoscaler does not track instance types and their associated CPU and Memory size. Hence, when you create your spot fleet, you have to use spot instance types that have the same CPU and memory size. If not, you might see unexpected results, since the cluster autoscaler does not know the scaled up capacity in the cluster.
Summary
Introducing spot instances in the infrastructure offers a way to reduce your monthly AWS bill significantly without sacrificing service reliability. There are various open-source tools available that make this possible.
