MailChannels Service Disruption: All The Gory Details
By Ken Simpson | 10 minute read

On April 22, 2024, at 05:30 UTC, our monitoring systems alerted us that SMTP connection times had spiked from the normal sub-1 second to over 7 seconds. This was the beginning of a significant service disruption. We know how critical email delivery is to your business and your customer relationships, which is why we want to be fully transparent about what happened, how we responded, and what we’re doing to prevent similar incidents in the future.
The Incident
Initial assessments showed a significant surge in email data originating from a small number of senders. Our on-call engineering team immediately began investigating and quickly brought additional resources online to handle the load. However, the email surge continued and began to overwhelm other components of our infrastructure. By 06:00 UTC, many customers were experiencing delays in email delivery.
The team determined that the sustained high loads were being caused by continuous retries of large emails that were unsuccessfully delivered during the initial disruption. To relieve pressure on the system, at 07:50 UTC the team temporarily blocked the domains generating the majority of the traffic surge. This allowed email queues to gradually recover.
By 17:20 UTC, email queues had returned to normal, though some messages submitted during the incident still faced slower delivery times as the backlog fully cleared. The entire MailChannels team remained dedicated to the issue for the remainder of the day, monitoring the situation closely.
Root Cause Analysis
After a thorough investigation of logs, MailChannels engineers determined that the underlying issue was caused by a recent change to how certain large email messages are handled within our SMTP processing pipeline. This change, combined with an unusually high influx of large messages from a handful of senders, exposed a vulnerability in our surge protection and auto-scaling capabilities.
The crux of the issue stemmed from how a specialized SMTP proxy manages memory for high throughput tasks using a memory pool allocation approach. The recent change exacerbated a latent O(n2) performance issue when processing very large messages, doubling the CPU load required to process large messages.
When a worker process becomes unresponsive due to this issue, a watchdog process restarts it, severing whatever SMTP connections were being handled by that worker. For performance reasons, our SMTP proxy uses an asynchronous IO architecture that can handle thousands of SMTP connections per worker process with minimal memory use. However, asynchronous IO has a weakness: if any individual operation such as memory management stalls the process for a long period of time, the handling of all connections slows down.
After the watchdog has reset the SMTP proxy worker process, the upstream mail servers whose connections were severed soon try sending the same messages again. On Monday, this flood of retries exacerbated the situation as a growing pile of messages from sending servers continuously hit the service, never being processed rapidly enough to resolve the backlog. The chart below illustrates the surge in SMTP connection latency triggered when this vulnerable code was hit by an initial surge of large messages:

Chart 1: This chart shows the amount of time (seconds) it takes for an SMTP client connecting to the MailChannels Outbound Filtering service to establish a connection and receive the SMTP banner response. The normal value for this duration is less than one second.
Initial assessments showed a significant surge in email data originating from a small number of senders. Auto-scaling brought significantly more capacity online, however, as senders re-attempted delivery of the same large messages over and over again, eventually no amount of scaling was able to clear the backlog.
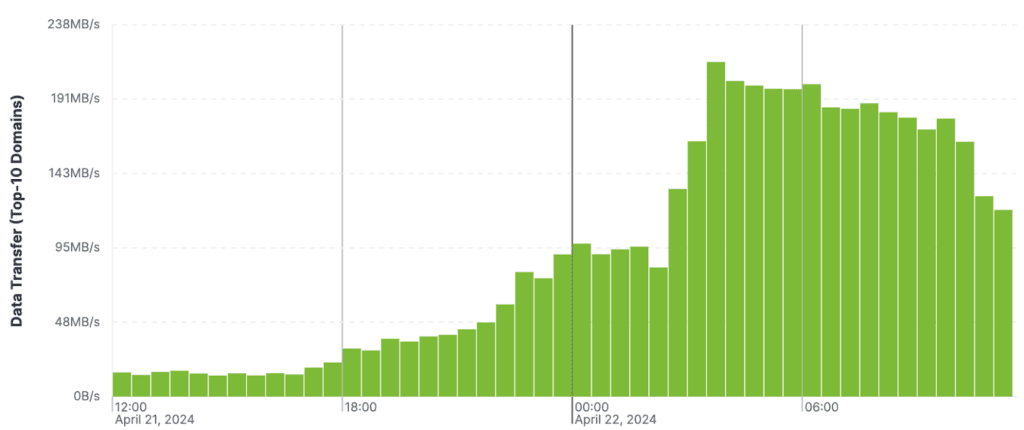
Chart 2: The combined data transfer rate of the top-10 sending domains grew from 16 MB/s to over 90 MB/s by just before midnight Pacific Time on April 22nd. Surges like this are not unheard of, but to see such a significant surge from just a handful of senders is somewhat unusual.
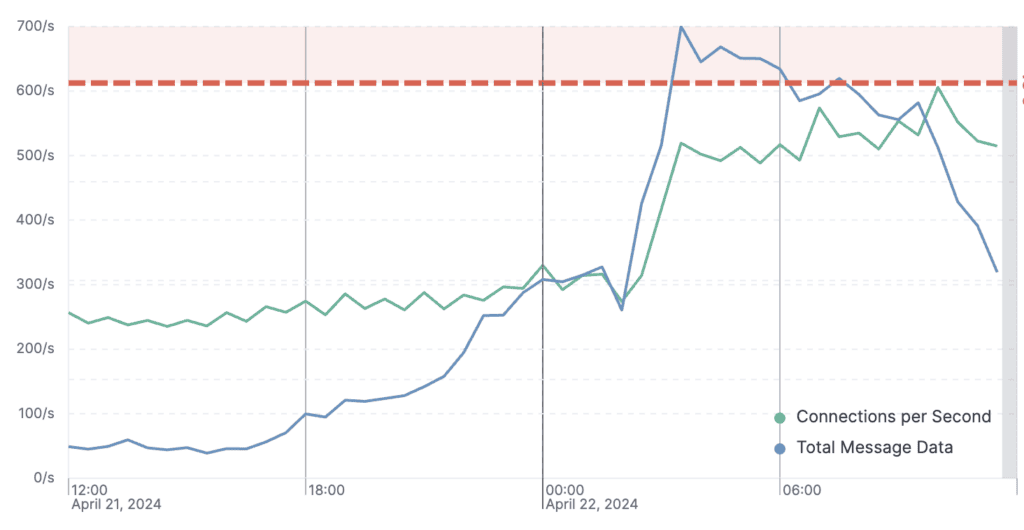
Chart 3: Although MailChannels infrastructure has effectively infinite scale with Amazon Web Services (AWS), we transfer data from edge nodes that have a bandwidth cap. At one point late in the evening on April 22nd, total bandwidth exceeded this cap (the red dashed line).
Timeline
All times below are in UTC:
April 22 06:00 – An transient alert was triggered as our monitoring service (Datadog) noticed elevated rates of process restarts. The alert resolved on its own.
April 22 06:30 – An initial “SMTP Down” alert was issued. The alert went away on its own as our auto-scaling and load management services took care of the initial surge in traffic.
April 22 07:08 – Our Indian operations team performed a harder reset of SMTP handling services in an attempt to get traffic flowing. Edge proxies were also restarted to rule out whether there were problems at our four geographically distributed edge locations.
April 22 08:59 – After these initial efforts to reduce service latency had failed, the VP of Operations and Technical Support was paged in North America and immediately began examining logs and service dashboards.
April 22 09:11 – On a hunch that the problem might be related to a recent change to the SMTP proxy software, this software was rolled back to an earlier version. Rolling back to the previous version took about 30 minutes because of internal processes that require verifying the correctness of each software change. These processes help to ensure the security and integrity of the service and cannot be avoided.
April 22 09:50 – Additional SMTP proxy capacity was manually added; this additional capacity augmented the auto-scaling that was already taking place to handle more traffic.
April 22 10:08 – Additional message queue capacity was added. Message queues receive messages from the SMTP proxies and since they use different software, it took longer for this layer of the system to run out of capacity, even with auto-scaling.
April 22 11:38 – The Lead Architect was paged and began working on software changes such as altering message handling policies aimed at restoring service.
April 22 11:50 – A message handling policy aimed at limiting email traffic from extremely high bandwidth senders was enabled. This emergency policy is an important circuit breaker the team developed a year ago in response to a similar service issue relating to large messages and is disabled except in times of extreme load.
April 22 15:14 – MailChannels CEO is notified and begins helping the team dig through data that might be helpful in identifying the root cause. The Lead Architect has a theory about the software change in the SMTP proxy that was rolled back hours earlier. Meanwhile, the support team is fielding a growing number of support requests from customers concerned to know when the storm will end.
April 22 16:45 – SMTP connection latency drops below the alert threshold and the service queues fall to acceptable levels. The round-trip delivery time for a typical message injected into the service drops to a few seconds – within normal operating parameters. The incident was now under control and the team shifted to stabilization efforts and the search for a root cause.
Technical Details
Warning: This section is intended for very technical readers
On the morning of Friday, April 19, MailChannels developers deployed a bug fix to the way we handle SMTP ‘dot-stuffing’. This fix was necessary to prevent some messages from having signatures for authenticated receive chain (ARC) headers computed incorrectly. However, this code change unintentionally worsened an existing performance issue during the processing of exceptionally large messages, something that would not show up as an issue under normal operating conditions.
Our SMTP proxy software employs a memory pool allocation strategy designed to handle memory efficiently for high throughput. Because it often handles thousands of SMTP sessions per second in a single worker process, handling memory efficiently is extremely important. For substantial memory allocations, such as those for large messages, the memory pool uses a linked list to allow individual reallocations back to the operating system. In contrast, smaller allocations are collectively freed when the pool is dismantled after the SMTP connection finishes.
The complication emerges when a very large email message, distributed over numerous buffers, is processed by the content filter. We must then navigate through the linked list for each buffer to locate and release its corresponding memory. This results in a time complexity of O(n2) as the number of buffers increases because of the way this memory deletion strategy is coded. And as any skilled developer knows, O(n2) can lead to explosive CPU consumption.
The recent code change mentioned above further necessitated keeping an additional copy of the message data, which doubled the computational burden at O(n2) for large messages. Although the fundamental issue of algorithmic complexity was already present, the extra buffers allocated for the dot-stuffing fix pushed the system to its limits, causing individual worker processes to become unresponsive for extended periods while memory was being freed. Although many worker processes run in parallel, each worker handles up to several hundred SMTP connections, so a long pause to free memory holds up many SMTP senders.
When a worker remains unresponsive for an extended period, a watchdog mechanism intervenes by restarting it. This action, however, forcibly terminates all SMTP connections managed by that worker, prompting upstream servers to resend those messages. This wave of retries, many involving large messages, exceeded the system’s processing capabilities, resulting in significant disruptions.
Since this problem only manifested under conditions of high load with large messages, it escaped detection during our routine testing and canary deployments, since our testing procedures did not exercise the software specifically to test its handling of a surge of large messages. The combination of the code change and an unusual influx of large messages created this critical situation.
Immediate Mitigation
As the dust settled on April 22nd, our team immediately took a few steps to stabilize our infrastructure and reduce the risk of a recurrence. The steps taken included:
- Reverting the software change that we believed was the root cause of the issue;
- Increasing processing capacity by 50% to ensure that we had substantially more processing capacity than normally required, in case our assessment of the root cause was incorrect;
- Adjusting load balancing settings to more evenly distribute traffic between areas of the infrastructure;
- Temporarily rate limiting sender domains that send very large amounts of email data in a short period of time with an emergency policy; and,
- Closely monitoring all aspects of system health continuously to ensure the problem had been fully resolved.
What’s next?
It could be said that our only job is to deliver email reliably for our customers. Everything else we do is window dressing. Therefore, we take service disruptions like this very seriously. To prevent recurrences, we are implementing the following improvements over the coming week:
- Enhancing rate limiting and traffic shaping to protect against sudden surges, even from a small number of senders;
- Improving auto-scaling to more intelligently add capacity when needed;
- Adding a new system to prioritize the delivery of smaller messages to reduce the impact of large message retries;
- Expanding load testing to better simulate massive influxes of large messages;
- Adding more granular monitoring and alerts to detect problems earlier;
- Performing regular disaster recovery drills to hone our incident response processes; and,
- Providing additional training for our nighttime staff to ensure a faster escalation to senior engineers next time.
At MailChannels, we pride ourselves on world-class reliability and deliverability. When we fall short of those standards, we believe in full transparency and decisive corrective action. We are committed to learning from this incident and coming back stronger than ever.
We know you place a huge amount of trust in us and we take that responsibility very seriously. Our entire company is dedicated to continuous improvement in pursuit of our mission – empowering you to have exceptional, secure communication with your customers.
If you have any other questions or feedback, please don’t hesitate to reach out. We are here 24/7/365 to support you.
