Inbound Spam Filtering vs. Outbound Spam Filtering
Inbound Spam Filtering Vs. Outbound Spam Filtering What’s the difference between Inbound and Outbound Email Filtering? Inbound Spam Filtering MailChannels Inbound Email Filtering Outbound Spam Filtering MailChannels Outbound Email Filtering...

Palinurus – A Helm chart conversion tool
...apps/v1 kind: Deployment metadata: name: nginx labels: app: nginx spec: replicas: 1 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx:1.7.9 ports: -...
Understanding Spam Filtering: Protecting Your Digital Space
...are several types of spam filters, including content filters, header filters, blocklist filters, and rules-based filters. Each type uses different criteria to identify and block spam emails. Can spam filters...

What is Spam Filtering
...Importance of Spam Filtering: While no spam filtering solution is 100% effective, a business email system without one is highly vulnerable. Efficient spam filters defend networks from various risks, including...

Is Consent Required for Spam Filtering? A GDPR Perspective for Hosts and ESPs
...risk or threat (e.g., spam or account compromise) Filtering is necessary to mitigate that threat The user’s rights and freedoms are not overridden by the filtering activity You do not...
How to Filter Emails Without Violating Privacy: A GDPR-Safe Approach for Hosts and ESPs
Introduction Filtering outbound email is essential for stopping spam, phishing, and abuse. But if your filtering practices inspect message content or metadata, are you violating your users’ privacy? In a...
What is Inbound Spam Filtering?
...spam emails sent daily, having an effective inbound spam filtering system in place is essential for maintaining secure and manageable inboxes. Understanding Inbound Spam Filtering Inbound spam filtering is essentially...

Why Outgoing Spam Filtering Can And Should Be Done Transparently
...capture and block spam that is sent over encrypted links. Filter out STARTTLS The second option is to have the transparent SMTP filter “filter out” the RFC3207 STARTTLS extended SMTP...
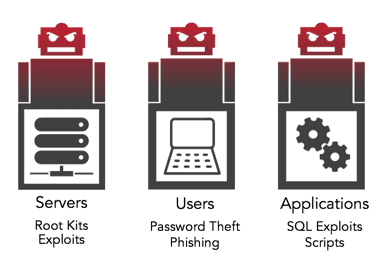
Securing Outbound Email vs. Filtering Inbound Spam
They’re not the same—and if you’re only filtering inbound email, you’re missing half the picture. When people talk about email security, they often think about inbound spam filtering—blocking junk mail,...

What is Outbound Spam Filtering
...outbound spam filter can identify the actual sender of each message, record long-term sender behavior, and look for suspicious patterns. Additionally, a top-tier outbound spam filter minimizes mistakes, as errors...

Stay updated with MailChannels
Subscribe to the MailChannels Blog to receive new blog posts in your inbox.
Cut your support tickets and make customers happier
